NVIDIAが「Chat with RTX」をリリース 使い方を解説
NVIDIAは2024年2月14日(日本時間)、ローカルで動作するRAG対応のチャットソフト「Chat with RTX」を発表しました。Chat with RTXは、個人や開発者に新しい方法で資料やデータにアクセスする手段を提供します。
この記事では、NVIDIAがリリースした「Chat with RTX」概要から使い方までを解説します。
Chat with RTXとは?

Chat with RTXは、NVIDIAがCES 2024で発表した大規模言語モデル(LLM)の技術デモです。LLMは、OpenAIのChatGPTやMicrosoftのCopilot、GoogleのGemini(旧:Google Bard)などで使われている技術です。
Chat with RTXでは検索拡張生成(RAG) と呼ばれる技術を用いて、ローカルのファイルを検索し、それらを活用した回答ができます。それが今回、実際にデモとしてダウンロード可能になりました。
次の動画は、NVIDIAが公開したChat with RTXのデモ動画です。
このデモアプリを使用すると、LLMを自分のドキュメント、ノート、ビデオなどに接続し、パーソナライズできるようになります。RTX acceleration、TensorRT-LLM、および検索拡張生成(RAG) を活用してチャットボットにクエリを送り、文脈に合った適切な回答を素早く得られます。
さらに、Chat with RTXはPC上でローカルに実行されるため、速くて安全な結果を得られます。
Chat with RTXは、テキスト、PDF、DOC/DOCX、XMLなどのさまざまなファイル形式をサポートしています。フォルダーを指定するだけで数秒以内にロードします。また、YouTubeのプレイリストのURLを入力すると、動画の字幕をを読み込み、コンテンツに関するクエリを実行できるようになります。
技術デモであるChat with RTXは、GitHubから入手可能なTensorRT-LLM RAG開発者リファレンスプロジェクトから構築されています。開発者はこのリファレンスを使用してRTXのための独自のRAGベースアプリケーションを開発し、展開できるとのことです。
Chat with RTXが役立つ場面
Chat with RTXのような技術は、さまざまなシーンで役立つことが期待されます。
研究者や学生は、論文や研究メモに素早くアクセスし、特定の情報を検索する際に時間を節約できます。ビジネスでは、重要なドキュメントやプレゼンテーション資料から迅速に情報を抽出し、意思決定を加速できます。
また、開発者はソースコードや技術文書内で特定の機能やAPIの使用方法を簡単に発見でき、コンテンツクリエイターは、ビデオの文字起こしから特定のトピックやセクションを素早く探し出せます。
Chat with RTXの使い方
インストール
Chat with RTXは、NVIDIAの公式サイトからダウンロードできます。公式サイトにアクセスし、[Download Now]をクリックするとダウンロードが始まります。
ファイルはZIP形式で約35GBあるので、ダウンロードには時間がかかります。

ダウンロードが完了したらZIPファイルを解凍します。ファイルサイズが大きいので解凍にも時間がかかります。私の環境では解凍に15分ほどかかりました。
CPU性能よりもストレージ速度が足を引っ張っていました。解凍後のフォルダーのサイズは約38GBでした。
Chat with RTXをインストールするには、管理者権限で``setup.exe``を実行します。
記事執筆時点でのバージョンはv0.2のようです。システムの互換性の確認が始まるので、しばらく待ちます。

Chat with RTXで利用されているソフトウェアのライセンスの同意画面が表示されるので、内容をよく読んで同意する場合は[AGREE AND CONTINUE]をクリックします。

インストールのオプションの画面が表示されます。Chat with RTXはMistral 7Bを使っているようです。また、ファイルを見てみると、LLaMA 13Bのモデルも対応しているようです。ここでは元々の設定のまま[NEXT]で進みました。

インストール場所の確認が表示されるので、とくに問題がなければそのままインストールします。
使い方
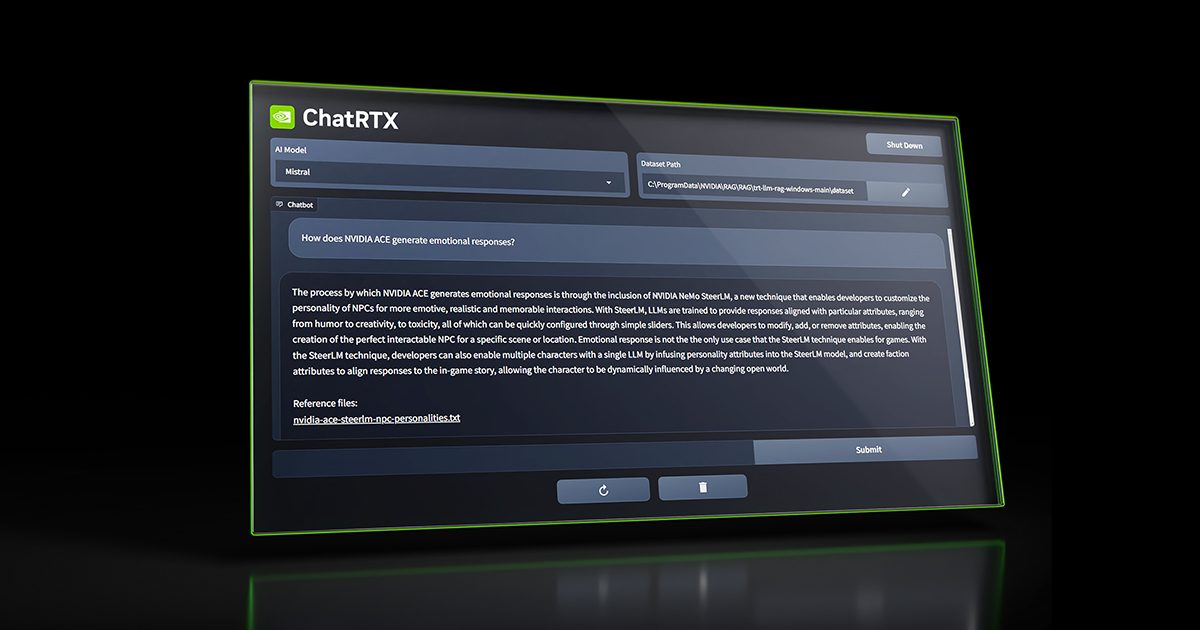
インストールが終わって起動すると、Webブラウザーが立ち上がってUIが表示されます。
[Dataset]で[YouTube URL]を選択し、OpenAIのDevDayの動画のURLを入力してみました。
ダウンロードアイコンをクリックして字幕データをダウンロードしてから「summarize this video」と入力したところ、動画の要約が表示されました。内容は概ね合っていそうです。RTX 3070 Tiで試したところ、生成速度は非常に高速でした。

summarize this video
The context information provided is a transcript of a video about a new feature being added to an app that allows users to interact with an AI assistant. The assistant is built using the GPT-4 Turbo model and can handle longer context lengths, provide more accurate responses, and give users more control over the model's behavior. The assistant can also handle function calling and provide reproducible outputs. The video also mentions the ability to view logprobs in the API in the coming weeks.
Reference files:
Title: OpenAI DevDay: Opening Keynote
Channel: OpenAI
Uploaded Date: 2023-11-06
[Select AI model]ではMistral 7B int4しか選択できませんでした。おそらく、筆者のPCに搭載されているGPUのVRAMが8GBしかないのが原因と思われます。VRAMが豊富にある環境ならLlama 2 13B int4も選択できるはずです。
[Dataset]で[Folder Path]を選択してみます。フォルダーを指定するとその中のファイルが読み込まれます。ファイル数が多いと埋め込み処理に時間がかかります。
現時点ではパスに日本語が含まれているとエラーが出るようです。今回は、GoogleのGeminiについての記事をPDFにしてフォルダーに入れてみました。

「What are the features of Gemini?」と尋ねたところ、適切な応答が返ってきました。日本語の記事だったのですが、問題なく回答できるようです。回答に使用したファイルへのリンクを示してくれるので、参照しやすいようになっています。

What are the features of Gemini?
Gemini is a new AI assistant that can be used on a smartphone. It is a new addition to the Google Assistant and can be used to create lists, plan events, and create new messages. It is powered by a new AI model called "Ultra 1.0" which has a higher accuracy and response speed than previous models. Gemini is also available as a mobile app for Android and iOS devices, allowing users to use it on the go.
Reference files:
GeminiアプリとGoogleアシスタントが統合!使い方と注意点を解説 - ろぼいんブログ.pdf
追加で日本語でも質問してみたところ、英語で応答が返ってきたものの内容は正確でした。

Geminiのアプリが2つある場合はどのようにして見分けられますか?
In the case where there are two Gemini applications installed on a smartphone, they can be distinguished by tapping on the icon. The icon for the Gemini application will be labeled "Gemini," while the icon for the Google Assistant application will be labeled "アシスタント."
Reference files:
GeminiアプリとGoogleアシスタントが統合!使い方と注意点を解説 - ろぼいんブログ.pdf
なお、文脈の保持はできないようです。前回の質問についての追加の質問をしても、「I apologize, but I need more context to understand what you are asking me to do. Can you please provide more information about the task or the specific topic you would like me to provide more information on?」というような回答が返ってきます。
また、VRAMの使用量は7.7GBほどでした。ただし、筆者の環境では4Kモニターを2枚接続しているため、Chat with RTX単体での使用量はもう少し少ないと思われます。
Chat with RTXを終了する
Chat with RTXを終了するには、UIの右上の電源アイコンをクリックするか、起動時に表示されるコマンドプロンプトでCtrl+Cを押します。
Chat with RTXの起動方法
Chat with RTXのインストールが完了すると、自動的に起動します。2回目以降の起動時は、Chat with RTXのショートカットが作成されているので、それをクリックすると起動します。
ショートカットが見当たらない場合は、次のバッチファイルを実行すると起動できます。インストーラーでインストール先を変更した場合は、その場所に合わせて読み替えてください。
C:\Users\<ユーザー名>\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\app_launch.bat起動に時間がかかる場合
Chat with RTXは前回起動したときの設定が保存されています。前回の起動時にファイル数の多いフォルダーを読み込んでいると、次回の起動時に埋め込みの処理から始まるため起動に時間がかかります。
その場合は、次の場所にある設定ファイルを書き換えることをオススメします。なお、インストール先として初期設定とは別の場所にインストールした場合は、その場所に合わせて読み替えてください。
C:\Users\<ユーザー名>\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\config\preferences.jsonpreferences.jsonの中身は次のようになっています。この``dataset.path``の値を、ファイル数が少なくパスに日本語が含まれない適当なフォルダーに変更することで、起動時間を短縮できます。
{ "dataset": { "path": "[Dataset]に指定したフォルダーのパス", "isRelative": false }}まとめ
「Chat with RTX」は、txtファイルに対応している一方でMarkdownファイルには対応していないようです。Markdownファイルに対応していると、ドキュメントの検索などに利用しやすくなるように思いました。
今後のアップデートや開発者コミュニティからのフィードバックによる改善に期待が高まります。
参考
おすすめアイテム
※このリンクを経由して商品を購入すると、当サイトの運営者が報酬を得ることがあります。詳細はこちら。
このサイトを支援する
Buy Me a CoffeeまたはGitHub Sponsorsで支援していただけると、サイトの運営やコンテンツ制作の励みになります。定期的な支援と一度限りの支援がありますので、お間違いのないようにお願いします。


-1.png&w=256&q=75)
生まれた時から、母国語よりも先にJavaScriptを使っていました。ネットの海のどこにもいなくてどこにでもいます。
Webフロントエンドプログラマーで、テクノロジーに関する話題を追いかけています。動画編集やプログラミングが趣味で、たまにデザインなどもやっています。主にTypeScriptを使用したWebフロントエンド開発を専門とし、便利で実用的なブラウザー拡張機能を作成しています。また、個人ブログを通じて、IT関連のニュースやハウツー、技術的なプログラミング情報を発信しています。













