Google I/O 2024の発表内容まとめ

2024年5月15日(日本時間)に開催されたGoogle I/O 2024では、GoogleのAIの情報を中心とした発表が行われました。Googleは、長年にわたるAIへの投資と研究開発の成果を披露し、AIモデル「Gemini」を中心とした新たな製品とサービスを発表しました。
Geminiのコンテキストウィンドウの拡大
Googleは10年以上前からAIに投資し、その進歩を遂げてきました。Google I/O 2023ではじめて発表されたGeminiは、テキスト、画像、動画、コードなど、さまざまな入力形式を理解し、複雑な推論ができる、マルチモーダルなAIモデルです。Geminiは、マルチモーダルであるだけでなく、100万トークンという、従来のAIモデルをはるかに凌駕する長文脈理解能力を備えています。膨大な量のテキストデータ、音声データ、動画データ、コードなどを処理し、複雑な質問に答えることを可能にします。
長文脈理解とは、AIモデルが一度に処理できる情報量のことで、トークン数で表されます。Gemini 1.5 Proは、100万トークンという、従来のAIモデルをはるかに上回る長文脈理解能力を備えており、さらに200万トークンまで拡張されました。たとえば、数百ページのテキスト、数時間の音声、1時間の動画、あるいは巨大なコードベース全体を、一度に処理することを可能にします。
Gemini 1.5 Proは主要なユースケースで品質が向上しました。より高速で安価なGemini 1.5 Flashも発表され、すでにGoogle AI Studioで利用できるようになっています。

Geminiの応用
Google検索は、Geminiによって大きく進化しました。従来のキーワード検索に加えて、AI Overviewsと呼ばれる機能が導入され、ユーザーはより複雑な質問を投げかけ、Web上の膨大な情報の中から最適な答えを得られるようになりました。AI Overviewsでは、質問に対する回答だけでなく、関連するさまざまな視点や、詳細情報へのリンクも提供されます。Google Search Labsとして提供されていた機能です。
たとえば、「ボストンで最高のヨガまたはピラティススタジオを見つけ、入門コースの料金とビーコンヒルからの徒歩時間について教えて」という複雑な質問に対して、評価の高いスタジオとその入門コースの料金、ビーコンヒルからの距離を分かりやすく表示します。さらに、スタジオの場所を地図上に表示するなど、視覚的に分かりやすい情報も提供します。
Ask Photos

Googleフォトでは、「Ask Photos」という機能が導入されます。自分の写真コレクションに対して、より複雑で自然な質問をできるようになりました。たとえば、「娘がいつ泳げるようになったのか」や、「娘の水泳の進歩を見せて」といった質問に対して、GeminiはGoogleフォトの写真、動画、メタデータなどを分析し、時系列に沿って整理された回答を返します。
Google Workspace
Google Workspaceでは、Geminiのマルチモーダル機能と長文脈理解能力を活用した、さまざまな新機能が導入されました。
Gmailでは、長文のメールスレッドを要約する機能、メールの内容に基づいて返信を提案する機能、添付ファイルの内容を分析し、関連する情報を整理する機能などが追加されました。スマートリプライもAIによって強化され、メールの文脈に応じた適切な返信を提案します。
Googleドキュメントでは、NotebookLMという研究・執筆ツールにGemini 1.5 Proが統合されました。膨大な資料をアップロードし、それらをもとに要約、FAQ、クイズなどを自動生成できます。また、Audio Overviewsという機能により、アップロードされた資料の内容に基づいて、音声による議論を生成することも可能です。
Geminiアプリ
Geminiアプリは、Googleの最新AIモデルに直接アクセスできる、パーソナルAIアシスタントです。テキスト、音声、カメラを使って、自然な形で対話できます。


今年の夏には、Liveと呼ばれる新しい音声会話機能が追加される予定です。Googleの最新の音声モデルを使用することで、より自然な会話が可能になります。ユーザーがGeminiの応答中に割り込むこともでき、Geminiはユーザーの話し方に合わせて柔軟に対応します。この機能は、前日にOpenAIが発表したGPT-4oの機能によく似ています。OpenAIのイベントの記事はこちらから確認できます。

さらに、Geminiを自分のニーズに合わせてカスタマイズできる、Gemsと呼ばれる機能も発表されました。Gemsは、特定のトピックに関するパーソナルアシスタントとして機能し、ユーザーは繰り返し同じようにGeminiと対話したい場合に、Gemsを使うことで時間を節約できます。こちらは、OpenAIのGPTsと呼ばれる機能に似ています。
Gemini Advancedでは、旅行計画機能が強化され、ユーザーの好みや条件を考慮した旅行プランを自動生成できます。Geminiは、Google検索、Googleマップ、Gmailなどから情報を収集し、最適な旅行プランを提案します。旅程の開始時間や訪問場所などを変更することもできます。
Project Astra・Imagen 3・Veo

Google DeepMindは次世代のAIエージェントの開発に重点を置いています。その一環として、Project Astraが発表され、より高度な空間認識や映像処理、記憶機能をもつAIエージェントのプロトタイプが紹介されました。Project Astraは、GoogleのAI技術を活用して、さまざまなタスクを自動化し、ユーザーの生活をサポートします。
デモでは、スマホのカメラの映像とユーザーの声にリアルタイムで反応するようすが披露されました。ホワイトボードに書かれたシステムの構成図を認識し、改善の提案をするなど、AIエージェントの機能が実演されました。
また、最新の画像生成AI「Imagen 3」と動画生成AI「Veo」も発表されました。Veoは高品質な1080Pビデオをテキストや画像、動画の指示から生成でき、さまざまなスタイルでの動画制作が可能になります。リアルタイムで音楽を生成できる「Music AI Sandbox」も発表され、イベントの冒頭では、AIで生成された音楽を使ったDJパフォーマンスが行われました。Veoの詳細には、こちらの記事を参照してください。

Android
Androidは、AIを中核としたスマホ体験を提供するために、今後数年かけて大きく進化していく予定とのことです。
Circle to Searchは、スマホの画面上のあらゆるものを検索できる機能です。アプリを切り替えることなく、画面上の情報に基づいて検索できます。たとえば、服の画像をCircle to Searchで検索すると、同じような服を販売しているオンラインストアを見つけられます。

Geminiは、Androidにシステムレベルで統合され、ユーザーが現在行っている操作を予測し、状況に応じてより役に立つ情報を提供します。ユーザーがスポーツのルールブックのPDFを開いている場合、GeminiはPDFの内容を理解し、ユーザーが質問したいことを予測して、関連する情報を提示します。靴を購入して返品が必要になった場合には、メールを検索して領収書を見つけ出し、返品の手続きを補助します。
Gemini Nanoは、Androidデバイス上で動作する軽量版のGeminiです。音声処理などのタスクをデバイス上で実行することで、プライバシーを保護しながら、高速な処理を実現します。また、ネットワーク接続がない場合でも動作します。Gemini Nanoを使って通話の内容をリアルタイムで解析し、迷惑電話を自動的にオンデバイス処理で検出する機能も発表されました。

AIの悪用防止と社会貢献
Googleは、AIの悪用防止技術についても発表しました。
レッドチーミングは、AIモデルの脆弱性を特定するために、意図的に攻撃を試みる手法です。Googleは、AIモデルの安全性を向上させるために、社内の専門家チームによるレッドチーミングを実施しています。
SynthIDは、AIによって生成された画像や音声に、検知不可能な電子透かしを埋め込む技術です。これにより、AI生成物が悪用されるのを防ぐことができます。Googleは、SynthIDをテキストや動画にも拡張し、さまざまなAI生成物の安全性を確保していく予定です。C2PA (Coalition for Content Provenance and Authenticity)は、デジタルコンテンツの出所や信憑性を明らかにするための標準規格です。Googleは、Adobe、Microsoftなどの企業と協力して、C2PAの開発と普及に取り組んでいるとのことです。
GoogleのAI技術は、さまざまな社会問題の解決に貢献しています。
AlphaFoldは、タンパク質の立体構造を予測するAIです。190か国、180万人の科学者がAlphaFoldを活用し、難病の治療法開発などに取り組んでいます。また、GoogleのAIは、80か国以上で洪水予測に役立てられています。Data Commonsは、世界中のデータを収集し、公開しているプロジェクトです。GoogleのAIは、Data Commonsのデータを分析し、国連の持続可能な開発目標の進捗状況を把握するために役立てられています。
Googleは、教育分野の課題解決にも取り組んでいるとしています。
LearnLMは、Geminiをベースに、学習用に調整されたAIモデルです。教育研究に基づいた、よりパーソナルで魅力的な学習体験を提供します。Learning Coachは、LearnLMを活用した、パーソナル学習アシスタントです。学習のステップバイステップガイダンスを受けたり、役に立つ練習問題や記憶術を学べます。Learning Coachは、単に答えを提示するのではなく、ユーザーが理解を深めることができるように設計されています。
YouTubeでは、LearnLMを使って教育動画をよりインタラクティブにする機能が開発されています。ユーザーは、動画の内容について質問したり、説明を受けたり、クイズに挑戦したりできます。
開発者向けの情報
AI Studioは、Googleが提供する無料のWebベース開発環境です。開発者は、AI Studioを使って、GeminiなどのAIモデルを使ったアプリケーションを簡単に開発できます。さまざまなモデルがあらかじめ用意されており、複雑な設定をすることなく、すぐにAI開発を始められます。
Vertex AIは、Google Cloudが提供する、エンタープライズ規模のAI開発プラットフォームです。Vertex AIでは、AI Studioと同じAIモデルを利用できますが、より高度な機能やセキュリティ機能が提供されています。大規模なデータセットを処理したり、複雑なAIモデルをトレーニングしたりするのに適しています。
オープンソースAIモデル「Gemma」
Gemmaは、Googleが開発したオープンソースのAIモデルです。Gemmaは、軽量ながら高い性能を誇り、さまざまなタスクに利用できます。
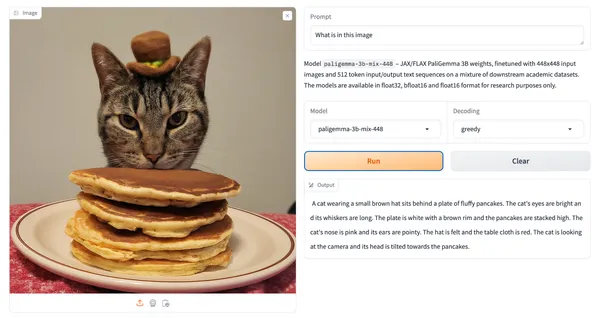
Gemmaは、70億パラメーターと20億パラメーターの2つのバージョンが提供されています。開発者は、Gemmaをカスタマイズして、独自のAIモデルを構築することもできます。270億パラメーターをもつGemma 2と、視覚情報に対応したVLM(Vision Language Model)も「PaliGemma」発表されました。

PaliGemmaの詳細については、こちらの記事で紹介しています。
まとめ
Google I/O 2024では、AIモデル「Gemini」を中心とした製品とサービスが発表されました。
Googleは、AI技術を責任ある形で開発し、社会に貢献していくことを表明しています。AIの悪用を防ぐための技術開発、AIによる社会問題の解決、教育分野への貢献など、さまざまな取り組みを進めているとのことです。


.D-9n0QZF_ZJb3My.png)